Why probability probably doesn’t exist (but it is useful to act like it does)
“概率”(probability)在日常生活里是个不易理解的概念。我们可以说某药在临床试验中有效率是 70%,却无法根据这个概率准确预测下一位患者的用药结局。不过至少这个概率看得见摸得着,临床试验参与者真有 70% 观察到疗效。更令人费解的例子如:天气预报称明天降水概率为 70%——第二天要么下雨要么不下雨,绝不可能“第二天”重复 100 次,其中有 70 天下雨(或目前无法观测)。剑桥大学统计学教授 David Spiegelhalter 认为“概率”未必客观存在,我们现下的“概率”概念包含了个人主观判断,部分反映的是我们对世界不确定性的认识或无知。纳西姆·塔勒布曾尝试用直观方法解释“随机性”(randomness),作为“概率”的可视化解释我觉得亦无不可——蒙特卡洛模拟(Monte Carlo Simulation)。现实无法重复,数学手段却能反复模拟,观察不同结局的发生概率。只是数学模拟又一定正确吗?Spiegelhalter 教授文末承认,概率未必存在,但假装它存在能解决许多问题。如果你对这个话题感兴趣,推荐斯坦福哲学百科(SEP)的 条目。
本世纪初,英国科研人员发现 伦敦的出租车司机大脑海马部位体积增大,可能是长期高强度执行空间导航任务的结果。由于海马萎缩是阿尔茨海默病的重要病理表现,美国研究者使用国家生命统计系统(National Vital Statistics System)的死亡数据,统计了 2020 至 2022 年间美国出租车、救护车司机因阿尔茨海默病死亡的情况。他们发现,相比其他 441 类职业,出租车、救护车司机死于阿尔茨海默病的比例最低——预期寿命相近的职业中亦然。而公交车司机、飞行员、船长这些以规划路径行进的运输工作人员,死于阿尔茨海默病的比例高得多,表明空间导航任务可能确实是潜在影响因素。此类流行病学横断面研究局限很大,尤其在因果推断方面,但我对这项研究结果很感兴趣:一是病理生理机制合理,二是似乎符合目前痴呆的 推荐预防措施。此外,研究者考虑全面,进行了多种敏感性分析弥补研究数据和设计缺陷,值得我们学习。
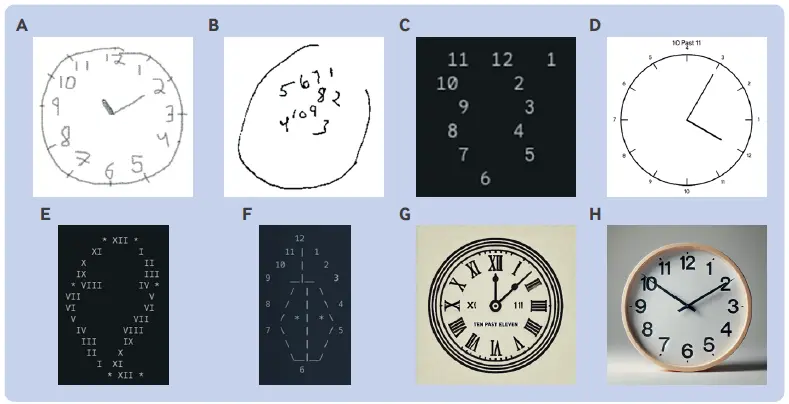
许多人争相研究人工智能(AI)取代医生可行性的时候,几位神经科医师先发制人,给几个人工智能大语言模型测定了认知功能,工具是常用的蒙特利尔认知评估(MoCA)量表。结果共 5 个模型参评,除 ChatGPT 4o 外全部被诊断为认知障碍,ChatGPT 4o 也只刚到及格线。所有模型的视觉空间/执行(visuospatial/executive)功能都很糟糕,文本分析和相关的抽象推理则表现正常,这符合我们根据大语言模型原理所作的推测。文章最有趣的是,研究者煞有介事地拟人化分析大模型的评测结果。比如额外的“Cookie Theft Picture”评估,所有大模型都未关注到图片上即将跌倒的男孩,研究者就评论这是缺乏同理心的表现,常见于额颞叶痴呆。幽默之余,这篇文章的意义在于向我们展示了人类与机器认知功能的可能差异——尤其是“绘制钟面”(clock drawing)任务,一些大模型的答案(见题图 G、H 部分)似乎表明,“他们”的理解与人类的理解或许不是一回事,更像是缺乏对细节了解的单纯“模仿”。